數據團隊如何兼顧發展與保持敏捷?
關鍵在於遵守design patterns並自動化相依性管理
(原文於 天下雜誌|數位科技 Blog 刊登)
數據需求增長是組織發展的縮影,然而在高速成長的同時,要如何避免失控的維運債拖累迭代的速度,就會是日益重要的課題。
本文我想分享處理這類議題積累的經驗,並說明這些design patterns可以如何省力。
為何這件事情重要?
在還沒開始發展前,一切都是愉快且沒有包袱的:新建設不用擔心打到東西、沒有要維持系統穩定的壓力、沒有新舊定義相容的問題,一切都是「新的」一切都是我說的算。
但隨著所做的東西變得日益重要,甚至成為了營運流程不可或缺的一部分,讓人瞻前顧後,投鼠忌器的「維運債」就逐漸浮出檯面,像是 :
- 舊table不敷使用,若想變更欄位,會不會不小心打到不該打到的東西?
- 上游資料源變更需要改所有的相關的下游table,不知怎麼盤起?
- 要控管Pipeline運算成本,但因為所有排程都用同一支service token,怎麼細拆到各別的專案來釐清費用歸屬?
- 要控管Dashboard query資料的成本,但因為所有的儀表板都是建立在同一個公用帳號下,怎麼細拆到各別的專案來釐清費用歸屬?
當既有的產出越來越多,團隊越來越大,釐清這些事情的成本就會成為隱藏的負擔,最終拖累發展新科技前進的速度。
更多細節
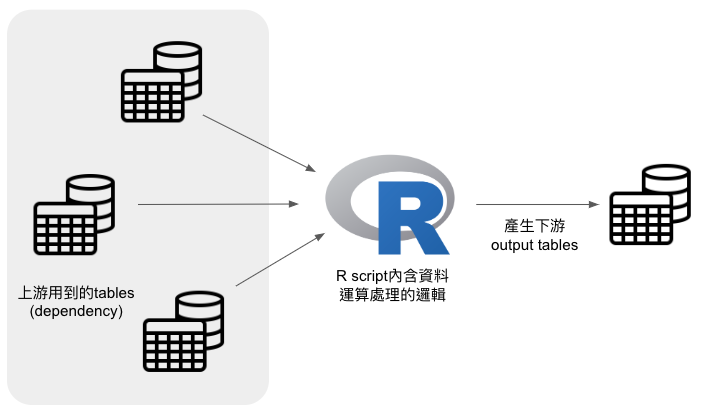
一般常見的pipeline架構如下圖,分成幾種組成:
- 排程控制 : 可以是Airflow/cron不拘
- 數據處理的邏輯 : R/python/SQL script,我也有看過用php/bash寫的XD
- SQL engine : 常用GCP Bigquery or AWS Athena等MPP(Massively Parallel Processing),主要是讓大資料在雲上跑,而不是壓在script的local端做,以避免scaling-up的問題
- 最後有一個呈現的介面 : 像是Datastudio、Tableau、Metabase等

其中在數據處理邏輯的script部分,又可以根據用到的資料源,與經過處理後產生的輸出結果,細分成上游與下游兩部分。
有了這些背景知識後,讓我們來看解決問題的關鍵:
解決問題的關鍵在於平日就有遵守特定的design patterns以利自動化的相依性(dependency)管理
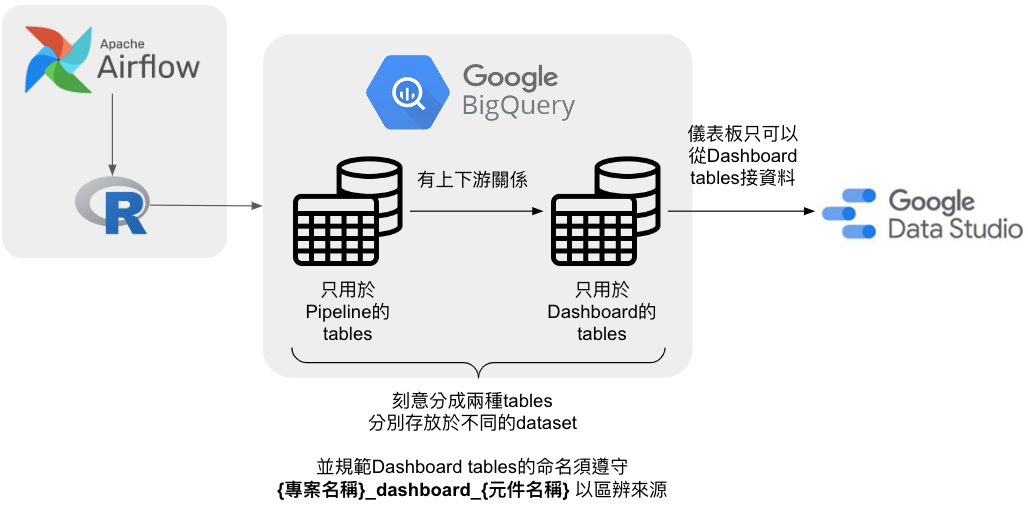
將tables分為pipeline與dashboard兩類,並適用不同的命名規則
用一張圖說明如下 :
這邊有幾個特點:
- 依照tables有無串接去做呈現,區分為pipeline與dashboard兩種tables,他們彼此為單向的上下游的關係,嚴禁dashboard tables作為其他pipeline tables的上游以免產生混淆
- 因為區分成兩種tables,故可以分別定義不同的命名規則。對於dashboard tables,建議採取的命名方式是 :
{專案名稱}_dashboard_{細部組成名稱}
這樣的命名法有幾個好處:
- 事後如果要計算某個儀表板他的query cost是多少,我們可以透過撈取SQL查詢紀錄內含有 “_dashboard_” 字樣來確認該查詢是儀表板發出來的 (因為pipeline tables名稱不會這樣取,且有規定儀表板只可以接dashboard tables)
- 可以從這個名字去解析該table是來自哪個專案蓋的儀表板,也可以細對到該儀表板內的哪個組成
- 對於外接到同一個儀表板的dashboard tables,以專案名稱作為prefix可方便將彼此有關聯的tables一起管理跟查找
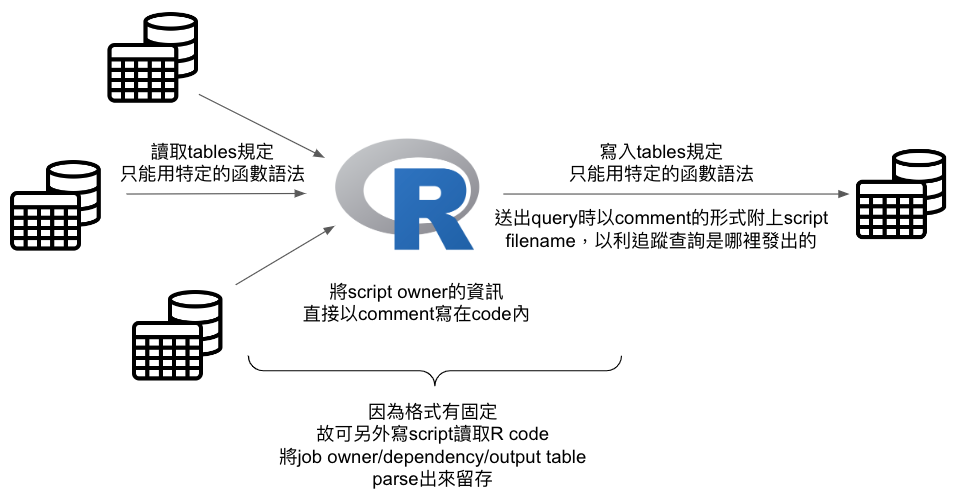
將讀取與寫入table的語法固定,並在script內直接加入owner資訊,以利建立程序將上下游及擁有者資訊做自動化留存
用一張圖說明如下 :
由於Data platform是多人協作的狀態,一天會有來自多人多次的push/pull,面對高速迭代,不太可能完全仰賴人工去紀錄哪個script用到什麼資料源、寫入到哪張table去。
一切都必須自動化,最好是code repo有更新就自動update相依性的紀錄。
以往這件事很難實現的障礙在於 :
- 大家在讀取與寫入tables用的語法千百種不固定
- owner資訊放在別處或是根本沒有寫,造成日久就不知道該script是誰的
- 送出的查詢只知道SQL的內容,但一個script往往會送出很多查詢,並沒有容易的方法將來源自同個script的查詢整理在一起
但只要做好這三件事,自動化parsing的程序便有可能實現 :
- 將讀取與寫入tables的語法固定下來,常見的做法是寫I/O function然後包在package內讓大家引用。
- 直接將code owner的資訊,以固定的格式直接寫在script內。
- I/O function在做查詢時,會將script的filename以comment的方式一併加到SQL內做送出,這樣做有利於事後追蹤該查詢是從哪個script發出來的。這對於需要計算query cost的情境會很有幫助。
結語
有時候回想,這些規則與規範如果拆開來檢視,其實乍看下好像也沒什麼,但經驗指出,當他們同時被一起用的時候,神奇的效果就會出現。
思想上,應避免萬靈丹思想,而是去問轉折點的前後做了什麼 : 數據團隊之所以能高效不被維運債拖累,並不會突然發生,而是平日的積累所致。